Virtual clusters provide the required computing abstraction to perform both HPC (High Performance Computing) and HTC (High Throughput Computing) with the help of a LRMS (Local Resource Management System), such as SLURM, to be used as a job queue, and a shared file system, such as NFS (Network File System).
Virtual elastic clusters in the Cloud can be deployed with Infrastructure as Code tools such as EC3 (Elastic Cloud Computing Cluster), which relies on the IM (Infrastructure Manager) to perform automated provisioning and configuration of Virtual Machines on multiple IaaS (Infrastructure as a Service) Clouds, both on-premises, such as OpenStack, or public, such as Amazon Web Services.
However, these virtual clusters are typically spawned in a single Cloud, thus limiting the amount of computational resources that can be simultaneously harnessed. With the help of the INDIGO Virtual Router, the DEEP Hybrid-DataCloud project is introducing the ability to deploy hybrid virtual elastic clusters across Clouds.
The INDIGO Virtual Router (VRouter) is a substrate-agnostic appliance, which spans an overlay network across all participating clouds. The network is completely private, fully dedicated to the elastic cluster, interconnecting its nodes wherever they are. The cluster nodes themselves require no special configuration since the hybrid, inter-site nature of the deployment is completely hidden from them by the vRouter.
In order to test the functionality of these hybrid virtual clusters, the deployment depicted in the figure below was performed:
First, both the front-end node and a working node were deployed at the CESNET Cloud site based on OpenStack. The front-end node includes both CLUES, the elasticity manager in charge of deploying/terminating nodes of the cluster depending on the workload, and SLURM as the LRMS. It also hosts the VRouter central point, which provides a configured VPN server. This is deployed through the IM based upon a TOSCA template that is publicly available. In case you don’t know, TOSCA stands for Topology Orchestration Specification for Cloud Applications and provides a YAML language to describe application architectures to be deployed in a Cloud.
The deployment of the computational resources at the UPV Cloud site, based on OpenNebula, included a VRouter, in charge of establishing the VPN tunnel to the VRouter central point, which was used as the default gateway for the working node of the cluster. Seamless connectivity to the other nodes of the cluster is achieved through the VPN tunnels. Again, this is deployed through the IM based upon another TOSCA template.
Notice that the working nodes are deployed in subnets that provide private IP addressing. This is important due to the lack of public IP across many institutions (we were promised a future with IPv6 that is being delayed). Also, the communications among the working nodes in each private subnetwork do use the VPN tunnels, for increased throughput.
Would you like to see this demo in action? Check it out in YouTube.
We are in the process of extending this procedure to be used with the INDIGO PaaS Orchestrator, so that the user does not need to specify which Cloud sites are involved in the hybrid deployment. Instead, the PaaS Orchestrator will be responsible for dynamically injecting the corresponding TOSCA types to include the VRouter in the TOSCA template initially submitted by the user. This will provide an enhanced abstraction layer for the user.
We plan to use this approach to provide extensible virtual clusters that can span across the multiple Cloud sites included in the DEEP Pilot testbed in order to easily aggregate more computing power.
And now that you are here, if you are interested in how TOSCA templates can be easily composed, check out the following blog entry: Alien4Cloud in DEEP.
Worried about the learning curve to introduce Deep Learning in your organization? Don’t be. The DEEP-HybridDataCloud project offers a framework for all users, including non-experts, enabling the transparent training, sharing and serving of Deep Learning models both locally or on hybrid cloud system. In this webinar we will be showing a set of use cases, from different research areas, integrated within the DEEP infrastructure.
The DEEP solution is based on Docker containers packaging already all the tools needed to deploy and run the Deep Learning models in the most transparent way. No need to worry about compatibility problems. Everything has already been tested and encapsulated so that the user has a fully working model in just a few minutes. To make things even easier, we have developed an API allowing the user to interact with the model directly from the web browser.
This is true for any kind of software development effort, regardless of whether it is framed under a big collaboration project or consisting in a humble application created for a confined audience. Software quality assurance (SQA), manages the development lifecycle of a given software product with the ultimate, and apparently simplistic, aim to produce better software. This is by no means an easy task and particularly paramount in research environments. Accessible and quality source code is the cornerstone to reproducible research as it provides the logic by which scientific results are obtained.
Openness, sustainability, readability or reliability are characteristics commonly associated with software quality, thus they should always reside in the mind of the developer at the time of writing the code. Readable source code leads to a smoother maintenance and increased shareability. A piece of software can be better sustained if the owners foster open collaboration by e.g. adhering to open and free licenses and providing clear guidelines for external contributions. Hence, the chances of survival of a software solution don’t only depend on increasing the collection of capabilities it exposes to the end users, as it was traditionally perceived, but also in consolidating those already available features in order to improve its reliability, and thus, the user experience itself. We shouldn’t forget that in the present era of social coding, the popularity of the software is tightly coupled with its accessibility and active support through public source code hosting platforms. Additionally, the transparency in the development process (e.g. continuous integration, security assessment) is key to build trust in our users.
In the DEEP-Hybrid-DataCloud (DEEP) project we strongly support these premises when developing our own software. We follow and contribute to the base of knowledge of SQA-related best practices from the “Common SQA Baseline Criteria for Research Projects” community effort (see this link and this link), applying them not only for the development of the core infrastructure software, but also within the scientific use cases involved in the project. Based on these guidelines, our source code is publicly accessible through GitHub (both deephdc and indigo-dc), distributed under the Apache 2.0 license. We have implemented DevOps-compliant pipelines to drive the development of both core and user applications, isolating beta features, in order to maintain a workable, production version that is automatically distributed –and readily available for external trial– to community-based software repositories such as PyPI or DockerHub. Along the way, source code is verified — tested and peer-reviewed — for each change targeted to production and subsequently deployed in a preview testbed, where it is validated within the DEEP solution.
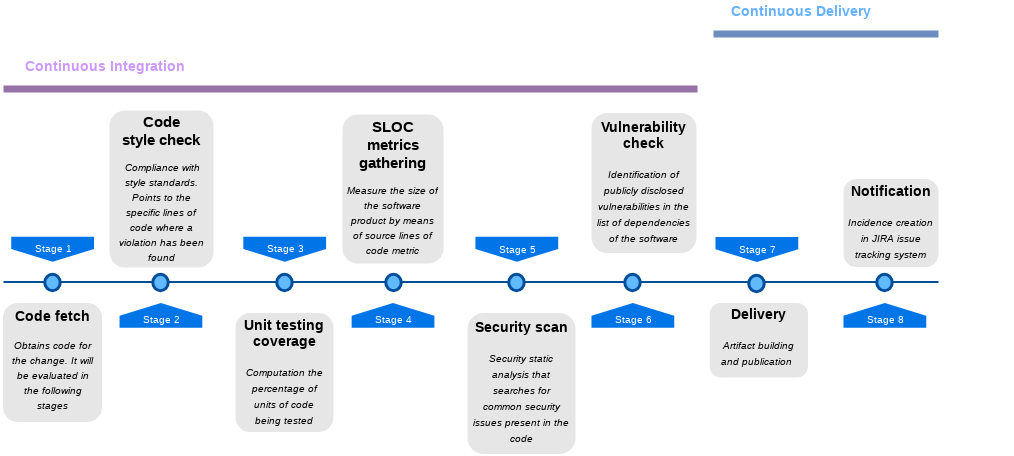
Different stages covered by the DevOps pipelines in DEEP-HybridDataCloud project
Nevertheless, our aim is to keep improving our current implementation and, in particular, investigating more consistent ways to validate machine learning applications and offer them in an inference as a service model through the extension of the current DevOps pipelines towards a continuous deployment approach. Our ultimate goal is to make quality-based machine learning applications readily available for public exploitation in the DEEP marketplace. Stay tuned!
udocker is a user tool to execute simple docker containers in user space, no root privileges required.
Containers and specifically Docker containers have become pervasive in the IT world, either for development of applications, services or platforms, the way to deploy production services, support CI/CD DevOps pipelines and the list continues.
One of the main benefits of using containers is the provisioning of highly customized and isolated environments targeted to execute very specific applications or services.
When executing or instantiating Docker containers, the operators or system administrators need in general root privileges to the hosts where they are deploying those applications or services. Furthermore, those are in many cases long running processes publicly exposed.
In the world of science and academia, the above mentioned benefits of containers are perfectly applicable and desirable for scientific applications, where for several reasons users often need highly customized environments; operating systems, specific versions of scientific libraries and compilers for any given application.
Traditionally, those applications are executed in computing clusters, either High Performance Computing (HPC) or High Throughput Computing (HTC), that are managed by a Workload Manager. The environment on those clusters is in general very homogeneous, static and conservative regarding operating system, libraries, compilers and even installed applications.
As such, the desire to run Docker containers in computing clusters, has arisen among the scientific community around the world but, the main issue to accomplish this has to do with the way Docker has to be deployed in the hosts, raising many questions regarding security, isolation between users and groups, accounting of resources, and control of resources by the Workload Manager among others.
To overcome the issues of executing Docker containers in such environments (clusters), several container framework solutions have been developed, among which is the udocker tool.
At the time of writing, udocker is the only tool capable of executing docker containers in userspace without requiring privileges for installation and execution, enabling execution in both older and newer Linux distributions. udocker can run on most systems with minimal Python versions 2.6 or 2.7 (support for Python3 is ongoing). Since it depends almost solely on the Python standard library, it can run on CentOS 6, CentOS 7 and Ubuntu 14.04 and later.
As such the main target of udocker are users (researchers) that want or need to execute applications packaged in Docker containers in “restricted” environments (clusters), where they don’t have root access and where support for execution of containers is lacking. udocker incorporates several execution methods thus enabling different approaches to execute the containers across hosts with different capabilities.
Furthermore, udocker implements a large set of commands (CLI) that are the same as Docker, easing the use of the tool to those that are already familiar with Docker. udocker interacts directly with the Dockerhub and run or instantiate images and containers in Docker format.
One of the features of the correct version is the ability to run CUDA applications in GPU hosts using official NVIDIA-CUDA Docker base images, through a simple options to set the execution mode to nvidia. Work is ongoing on the design to have MPI applications to be executed in the most easiest possible way.
udocker lives in this git repository, the Open Access paper can be found here. A slide presentation with details of the tool and a large set of examples can be found here
Many research areas are being transformed by the adoption of machine learning and deep learning techniques. Research e-Infrastructures should not neglect this new trend, and develop services that allow scientists to employ these techniques, effectively exploiting existing computing and storage resources.
The DEEP-Hybrid-DataCloud (DEEP) is paving the path for this transformation, providing machine learning and deep learning practitioners with a set of tools that allow them to effectively exploit the existing compute and storage resources available through EU e-Infrastructures for the whole machine learning cycle.
Alien4Cloud® is an advanced cloud management tool that aims at simplifying the composition (both visual and text), management (e.g. source storing/versioning/editing), handling, and deployment (deploy, undeploy, update) of cloud topologies described using the TOSCA specification language. Alien4Cloud® supports users (with different roles) who can utilize either basic TOSCA template components or full TOSCA template topologies to deploy their own cloud infrastructures.
Alien4Cloud®'s TOSCA visual editor
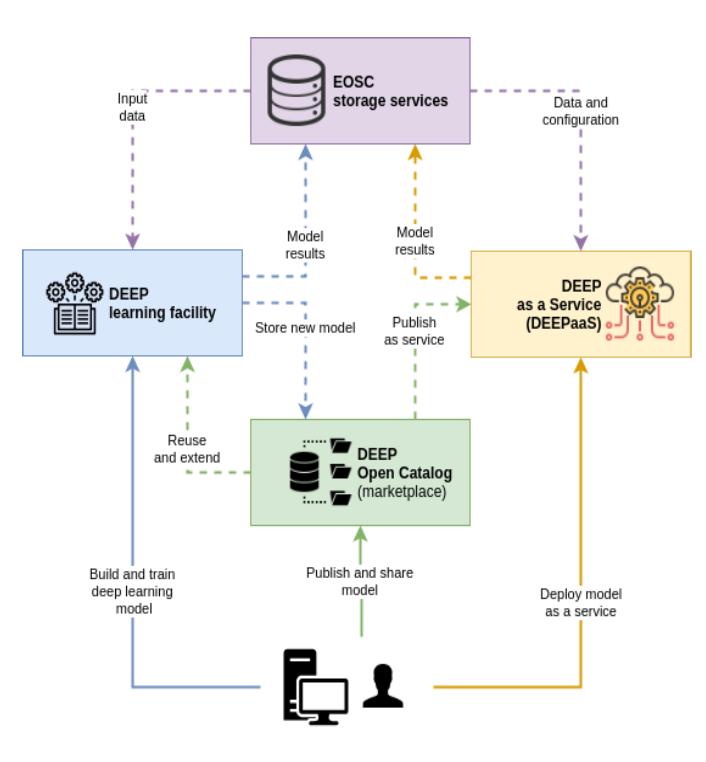
The DEEP Hybrid DataCloud project integrates Alien4Cloud® as the main component that allows our users to interact with the rest of the infrastructure. Figure F1 shows a custom infrastructure loaded from an existing topology template file that represents a small Kubernetes® cluster running the DEEPPaaS application. You can find more details about DEEP and the work being done at http://www.deep-hybrid-datacloud.eu. Diagram D1 depicts the role of the cloud management tool in the project. Alien4Cloud® is already a usable part of the project, please be sure you check our public demos on Youtube to see it in action.
The Alien4Cloud® role in DEEP
Since Alien4Cloud® allows functionality extension by the means of plugins, we developed one freely available on Github that connects it with the INDIGO PaaS Orchestrator used in DEEP. The Github repository doesn’t contain only the code for the orchestrator plugin, it also includes the Dockerfile necessary to create a Docker image (prebuilt at https://hub.docker.com/r/indigodatacloud/alien4cloud-deep) that includes all the components needed for deployment and use in DEEP:
The normative TOSCA types adapted from Openstack’s version.
The custom TOSCA types created during the INDIGO-DataCloud project and being updated during DEEP.
If you find our project interesting, stay tuned for more. There are new and exciting features coming up. We are currently working on:
Extending the TOSCA support in the Alien4Cloud® parser, we plan to support normative TOSCA 1.2
Improve the user experience with the graphical TOSCA editor.
Integrate the TOSCA parser from newer Alien4Cloud® versions into the INDIGO PaaS Orchestrator, with the normative support in both components, ensuring interoperability between the two components.
While you are here, you might want to take a look at a short video to help you get started with our Docker release (starting with the Docker image pull).
First part: Running a module locally for prediction
Deep Learning is nowadays at the forefront of Artificial Intelligence, shaping tools that are being used to achieve very high levels of accuracy in many different research fields. Training a Deep Learning model is a very complex and computationally intensive task requiring the user to have a full setup involving a certain hardware, the adequate drivers, dedicated software and enough memory and storage resources. Very often the Deep Learning practitioner is not a computing expert, and want all of this technology as accessible and transparent as possible to be able to just focus on creating a new model or applying a prebuild one to some data.
With the DEEP-HybridDataCloud solutions you will be able to start working from the very first moment!
The DEEP-HybridDataCloud project offers a framework for
all users, and not just for a few experts, enabling the transparent training,
sharing and serving of Deep Learning models both locally or on hybrid cloud
system.
The DEEP Open Catalog (https://marketplace.deep-hybrid-datacloud.eu/, also known as “marketplace”) provides the
universal point of entry to all services offered by DEEP. Its offers several
options for users of all levels to get acquainted with DEEP:
Basic
Users can browse the DEEP Open Catalog, download a
certain model and apply it to some local or remote data for
inference/prediction.
Intermediate Users
can also browse the DEEP Open Catalog, download a model and do some training
using their own data easily changing with the parameters of the training.
Advanced Users can
do all of the above. In addition, they will work on more complex tasks, that
include larger amounts of data.
The
DEEP-HybridDataCloud solution is based on Docker containers packaging already
all the tools needed to deploy and run the Deep Learning models in the most
transparent way. No need to worry about compatibility problems,
everything has already been tested and encapsulated so that the user has a
fully working model in just a few minutes.
To make things even easier, we have
developed an API allowing the user to
interact with the model directly from the web browser. It is possible to
perform inference, train or check the model metadata just with a simple click!
Let’s see how all this work!
In this post we will show how to download and use
one of the available models from the DEEP Open Catalog in our local machine.
These instructions will assume the user is running on linux but the docker
containers can run on any platform.
First we browse the catalog and click on the model
we are interested in among the many that are already in place. Once we click on
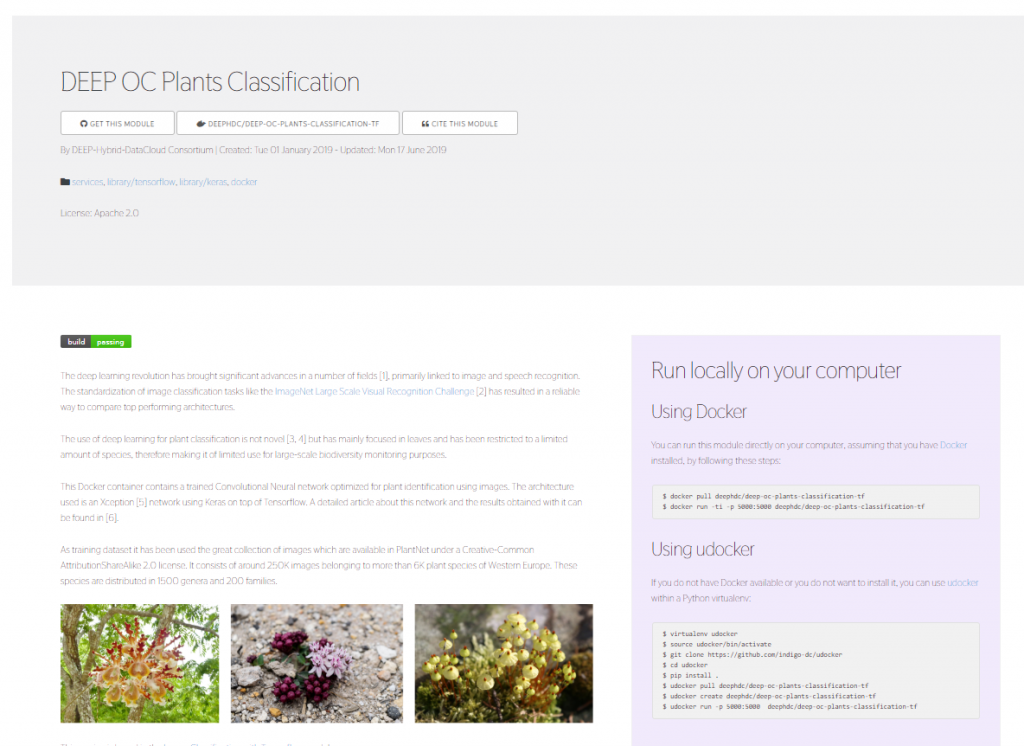
the model of our choice we will see something similar to this:
In this case we have selected a module classifying
plant images according to their species using a convolutional neural network
architecture developed in Tensorflow. Under the name of each of the modules in
the DEEP Open Catalog we find some useful links:
Link
to the GitHub repository including the model source code
Link
to the Docker Hub repository of the docker containing all the needed software
configured and ready to use
In
case this is a pretrained model, a link to the original dataset used for the
training.
Before starting we need to have
either docker or udocker installed in our computer. We will be using udocker
since it allows to run docker container without requiring root privileges. To
install udocker you can just follow this very simple instructions:
virtualenv udocker
source udocker/bin/activate
git clone https://github.com/indigo-dc/udocker
cd udocker
pip install .
We can now just follow the
instructions on the right part of the module page and type the following
commands:
udocker run -p 5000:5000 deephdc/deep-oc-plants-classification-tf
This will download (pull) the
docker container from Docker Hub and run it on our local machine. The run methods includes the option -p 5000:5000 which maps the port 5000 from our local
server into the port 5000 in the container.
We have now the DEEP API running
on our localhost!
You can go to your preferred web
browser and enter localhost:5000 in the address bar. This will open the DEEP as
a Service API endpoint. It looks like this:
As you can see in the image different
methods can be chosen. You can either return the list of loaded models (in this
case we are just running the plant classification example) or the metadata of
your models. You can also do some prediction on some plant image of your
interest or even train the classification neural network on a completely new
dataset. All this directly from your web browser.
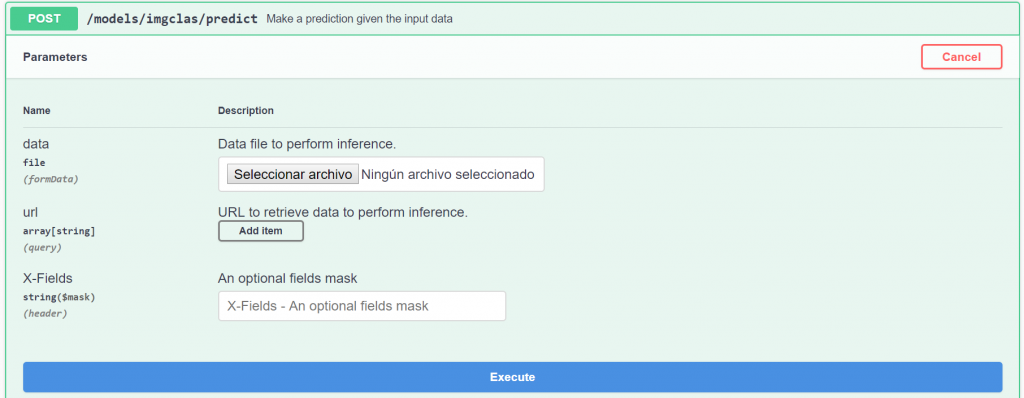
Let’s now try out the
prediction method. We can either use a local file or the URL to some online
plant image to perform the classification. For this example we will use a
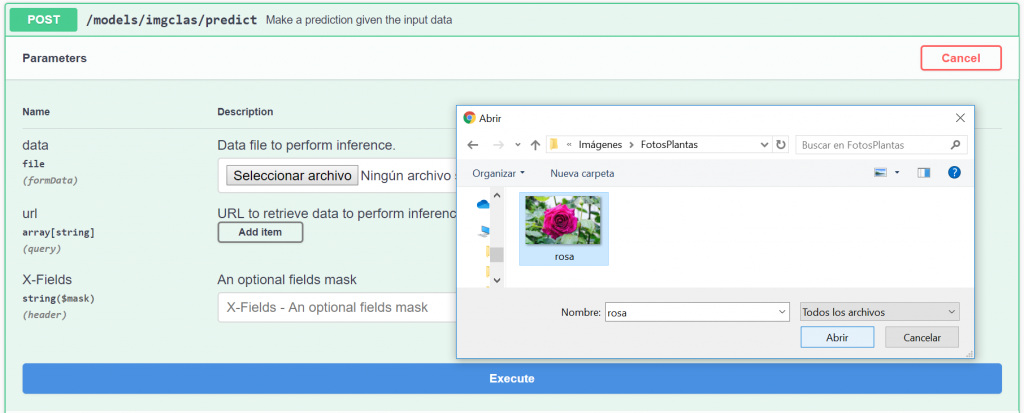
locally stored image.
We click on Select
File and browse our file system for the image we are interested in. In this
case we will use the image of a rose. If you want to reproduce this example you
can find the image here.
Now that we have selected the image we can click on Execute. The first time we perform a prediction with a given model the process takes a little while since the Tensorflow environment must be initialized. Afterwards, the prediction will be extremely quick (less than one second in many cases).
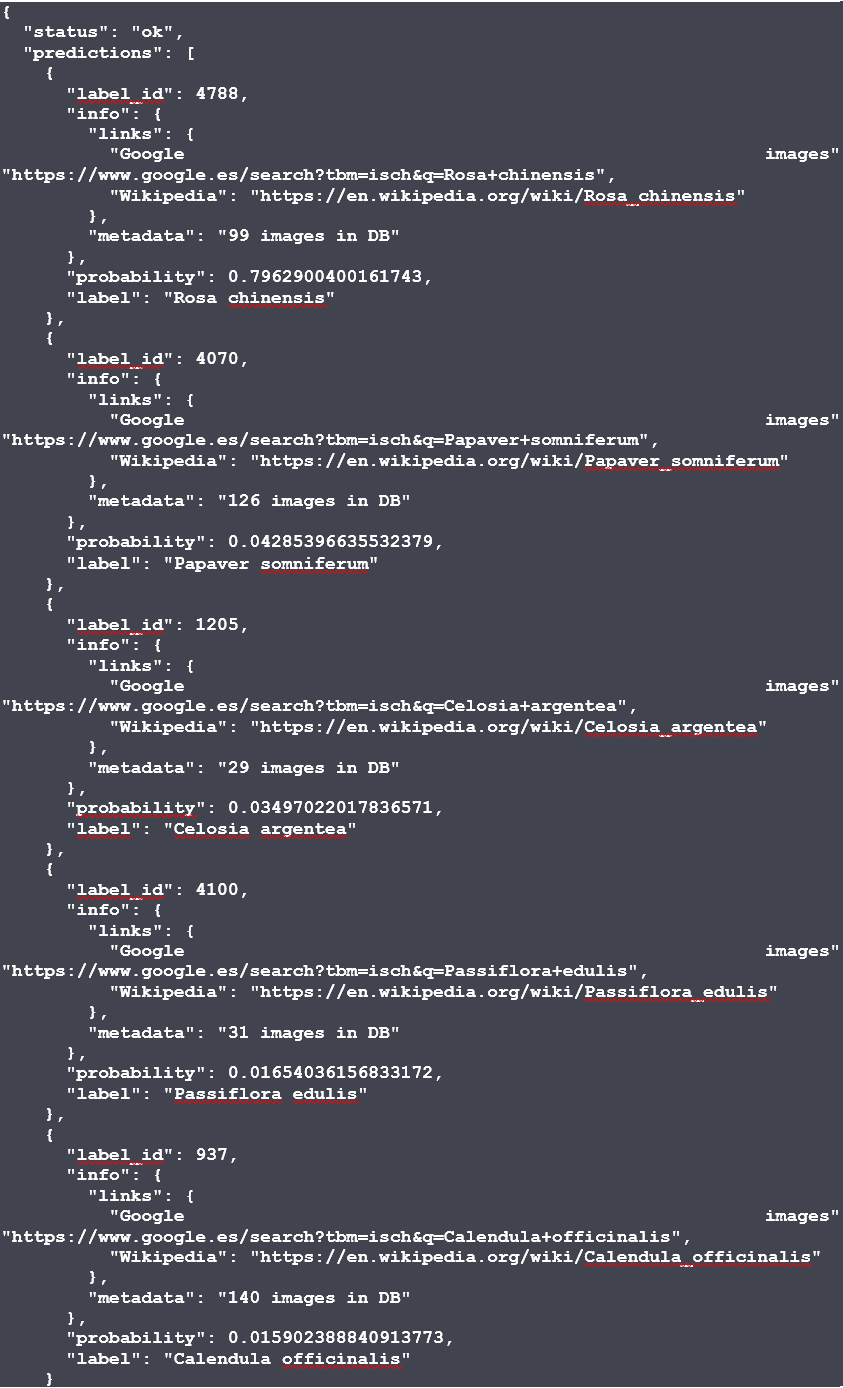
The prediction for our roses gives us the following output:
The result shows us the 5 most
probable species. The most probable one is the Rosa Chinensis with a
probability of 80%. Our module has predicted correctly! Together with the
prediction we can find a link pointing to Wikipedia to check the species.
The output is given in JSON format that can be very easily
integrated with any other application needing to access the results.
In this example we have seen how to use one of the DEEP-HybridDatacloud modules running a Deep Learning model in just a few simple steps on our local machine.
If you want more detail, you can find the full documentation here.
In next posts we will see how to train a model using the DEEP API and how to run on a cloud system. Stay tunned!
The
European Open Science Cloud (EOSC) aims to be the Europe’s virtual
environment for all researchers to store, manage, analyse and re-use
data for research, innovation and educational purposes.
Funded
by the EC, the projects are aimed at developing cloud-oriented
scalable technologies capable of operating at the unprecedented scale
as required by the most demanding, data intensive, research
experiments in Europe and Worldwide.
Thanks to the service components developed by INDIGO, researchers in Europe are now using public and private cloud resources to handle large volume data that enables new research and innovations different scientific disciplines and research fields. In particular, many INDIGO services are included – or in the process to be included – in the unified service catalogue provided by the EOSC-hub project, endeavoured putting in place the basic layout for the European Open Science Cloud.
Built upon the already existing INDIGO service components, DEEP released Genesis a set of software components enabling the easy development and integration of applications requiring cutting-edge techniques such as artificial intelligence (deep learning and machine learning), data mining and analysis of massive online data streams. These components are now available as a consistent and modular suite, ready to be included in the service catalogue.
The INDIGO service components are also the building blocks of Pulsar, the first XDC release, featuring new or improved functionalities that cover important topics like federation of storage resources, smart caching solutions, policy driven data management based on Quality of Service, data lifecycle management, metadata handling and manipulation, optimised data management based on access patterns. Some of them ready to be included in the service catalogue.
Suitable to run in the already existing and the
next generation e-Infrastructures deployed in Europe, the INDIGO,
DEEP and XDC solutions have been implemented following a
community-driven approach by addressing requirements from research
communities belonging to a wide range of scientific domains: Life
Science, Biodiversity, Clinical Research, Astrophysics, High Energy
Physics and Photon Science, that represent an indicator in terms of
computational needs in Europe and worldwide.
This
is exactly the way forward for EOSC: an advanced and all-encompassing
research environment that founds its core mission on
community-driven open source solutions.
The first DEEP-HybridDataCloud software release is out!
The DEEP-HybridDataCloud project is pleased to announce the availability of its first public software release, codenamed DEEP Genesis. The release notes can be found here.
This release comes after an initial phase of requirement gathering which involved several research communities in areas as diverse as citizen science, computing security, physics, earth observation or biological and medical science. This resulted in the development of a set of software components under the common label of DEEP as a Service (DEEPaaS) enabling the easy development and integration of applications requiring cutting-edge tecniques such as artificial inteligence (deep learning and machine learning), data mining or analysis of massive online data streams. These components are now released into a consistent and modular suite, with the aim of being integrated under the EOSC ecosystem.
DEEP Genesis provides open source modules to allow users from research communities to easily develop, build and deploy complex models as a service at their local laptop, on a production server or on top of e-Infrastructures supporting the DEEP-Hybrid-DataCloud stack.
High-level modules covering three types of users:
Basic users can browse and download already built-in models and reuse them for training on their own data.
Intermediate users can retrain the available models to perform the same tasks but fine tuning them to their own data.
Advanced users can develop their own deep learning tools from scratch and easily deploy them within the DEEP infrastructure.
All models can be exposed in a friendly front-end allowing an easy integration within larger scientific tools or mobile applications thanks to a RESTful API (DEEPaaS API). More details can be found here.
Key components of the release:
The DEEP Open Catalogue where the single users and communities can browse, store and download relevant modules for building up their applications (such as ready to use machine learning frameworks, tutorial notebooks, complex application architectures, etc.).
A runtime engine able to supply the required computing resources and deploy related applications.
The DEEP PaaS layer coordinating the overall workflow execution to select the appropriate resources (cloud and others, HPC, HTC) and manage the deployment of the applications to be executed.
The DEEP as a Service solution offering the application functionality to the user.
All the DEEP components are integrated into a comprehensive and flexible architecture that could be deployed and exploited following the user requirements. The DEEP Authentication and Authorization approach follows the AARC blueprint, with support for user authentication through multiple methods thanks to the INDIGO IAM user authentication (SAML, OpenID Connect and X.509), support for distributed authorization policies and a Token Translation Service, creating credentials for services that do not natively support OpenID Connect.
The DEEP-HybridDataCloud software is built upon the INDIGO-DataCloud components, and is released under the Apache License Version 2.0 (approved by the Open Source Initiative), except for the modifications contributed to existing projects, where the corresponding open source license has been used. The services can be deployed on both public and private cloud infrastructures. Installation, configuration guides and documentation can be consulted here. The initial set of ready-to-use models from a variety of domains can be found at the DEEP Open Catalogue.
Get in touch
If you want to get more information about the scientific applications adopting the DEEP-Hybrid-DataCloud solutions or you want to become one, please contact us!








{kind=link}