This is true for any kind of software development effort, regardless of whether it is framed under a big collaboration project or consisting in a humble application created for a confined audience. Software quality assurance (SQA), manages the development lifecycle of a given software product with the ultimate, and apparently simplistic, aim to produce better software. This is by no means an easy task and particularly paramount in research environments. Accessible and quality source code is the cornerstone to reproducible research as it provides the logic by which scientific results are obtained.
Openness, sustainability, readability or reliability are characteristics commonly associated with software quality, thus they should always reside in the mind of the developer at the time of writing the code. Readable source code leads to a smoother maintenance and increased shareability. A piece of software can be better sustained if the owners foster open collaboration by e.g. adhering to open and free licenses and providing clear guidelines for external contributions. Hence, the chances of survival of a software solution don’t only depend on increasing the collection of capabilities it exposes to the end users, as it was traditionally perceived, but also in consolidating those already available features in order to improve its reliability, and thus, the user experience itself. We shouldn’t forget that in the present era of social coding, the popularity of the software is tightly coupled with its accessibility and active support through public source code hosting platforms. Additionally, the transparency in the development process (e.g. continuous integration, security assessment) is key to build trust in our users.
In the DEEP-Hybrid-DataCloud (DEEP) project we strongly support these premises when developing our own software. We follow and contribute to the base of knowledge of SQA-related best practices from the “Common SQA Baseline Criteria for Research Projects” community effort (see this link and this link), applying them not only for the development of the core infrastructure software, but also within the scientific use cases involved in the project. Based on these guidelines, our source code is publicly accessible through GitHub (both deephdc and indigo-dc), distributed under the Apache 2.0 license. We have implemented DevOps-compliant pipelines to drive the development of both core and user applications, isolating beta features, in order to maintain a workable, production version that is automatically distributed –and readily available for external trial– to community-based software repositories such as PyPI or DockerHub. Along the way, source code is verified — tested and peer-reviewed — for each change targeted to production and subsequently deployed in a preview testbed, where it is validated within the DEEP solution.
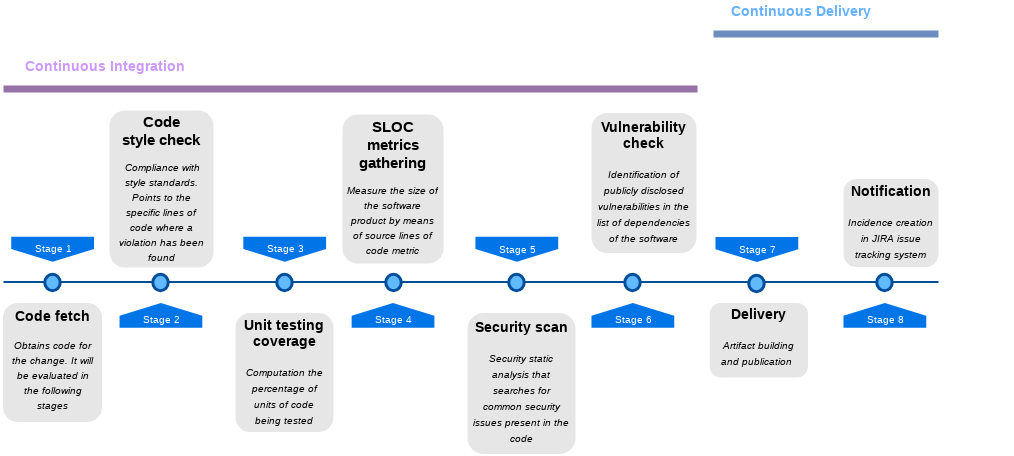
Different stages covered by the DevOps pipelines in DEEP-HybridDataCloud project
Nevertheless, our aim is to keep improving our current implementation and, in particular, investigating more consistent ways to validate machine learning applications and offer them in an inference as a service model through the extension of the current DevOps pipelines towards a continuous deployment approach. Our ultimate goal is to make quality-based machine learning applications readily available for public exploitation in the DEEP marketplace. Stay tuned!