
- New platform release allows data scientists and machine learning practitioners to build, develop, train and deploy machine learning services easily, with a comprehensive set of tools and services covering the whole machine learning application lifecycle.
- The new DEEP as a Service allows to deploy machine learning models as services, following a serverless approach, with horizontal scalability.
- Redesigned marketplace allows to train existing modules easily.
It is a pleasure to announce that the DEEP-HybridDataCloud project has published its second software release and platform, code named DEEP Rosetta. DEEP Rosetta expands on the first version of software generated by the project, called DEEP Genesis, enlarging its functionalities to cover the whole machine learning cycle, enhancing the stability of the different components and adding new features. Developing, training, sharing and deploying your model has never been easier!
All the changes in this new release are oriented towards the common project goal of easing the path for the scientific communities to develop, build and deploy complex models as a service at their local laptop, on a production server or on top of e-Infrastructures supporting the DEEP-Hybrid-DataCloud stack.
As in the previous release, the DEEP components are integrated into a comprehensive and flexible architecture that can be deployed and exploited following the user requirements.
Comprehensive set of services for machine learning
- The DEEP training facility, accessible through the DEEP training dashboard allows data scientists to develop and train their models, with access to latest generation EU computing e-Infrastructures.
- DEEP as a Service is a fully managed service that allows to easily and automatically deploy the developed applications as services, with horizontal scalability thanks to a serverless approach. The pre-trained applications that are published in the catalog are automatically deployed as services to make them available for general use.
- DEEP Open Catalog and marketplace comprises a curated set of applications ready to use or extend, fostering knowledge exchange and re-usability of applications. This open exchange aims to serve as a central knowledge hub for machine learning applications that leverage the DEEP-Hybrid-DataCloud stack, breaking knowledge barriers across distributed teams. Moreover, pre-configured Docker containers, repository templates and other related components and tools are also part of this catalog.
- DEEPaas API enables data scientists to expose their applications through an HTTP endpoint, delivering a common interface for machine learning, deep learning and artificial intelligence applications.
The platform has been extended to support asynchronous training, allowing to launch, monitor, stop and delete the training directly from your web browser. The trained models to perform inference can now be chosen from the models available in the training history. All the documentation on these new features has been accordingly updated here.
In addition, the user friendly training dashboard allows now to easily and transparently deploy the modules in a cloud environment. From the dashboard, the user can choose the resources needed for the deployment in terms of memory, type of processing unit (CPU or GPU), the storage client to be used or even to manually configure the scheduling.
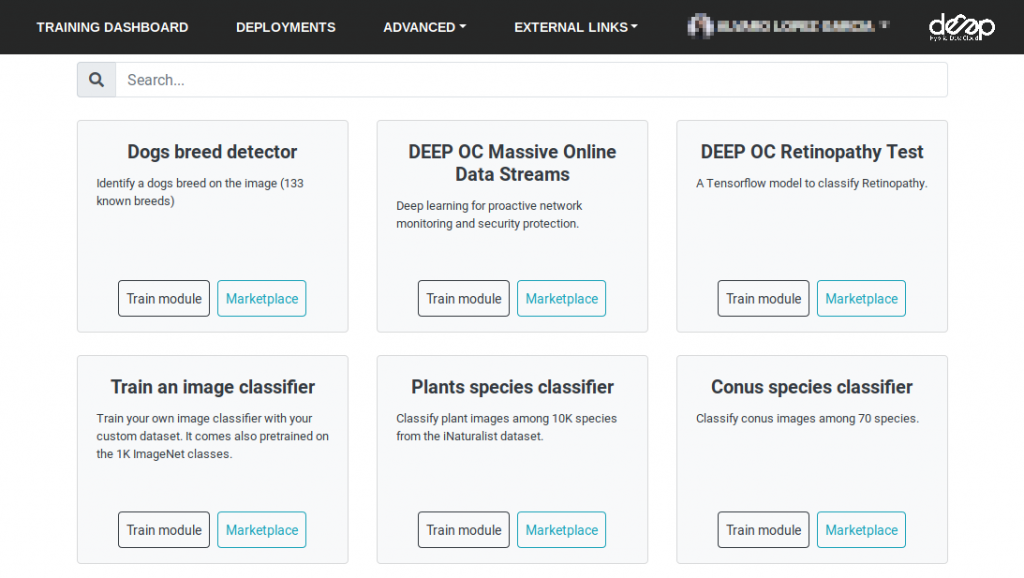
The DEEP Open Catalogue has been renewed with a more appealing design, improving the organisation of the modules and the general site interactivity.
The DEEP Rosetta release consists of:
- 10 products distributed via 22 software packages and tarballs supporting the CentOS 7, Ubuntu 16.04 and 18.04 operating systems.
- 15 fully containerised ready-to-use models from a variety of domains available at the DEEP Open Catalogue.
The release notes can be found here. The full list of products together with the installation, configuration guides and documentation can be consulted here.
The EOSC ecosystem
The release components have been built into a consistent and modular suite, always with the aim of being integrated under the EOSC ecosystem. As part of our integration path into the EOSC, we have published four different services and components in the EOSC portal:
- DEEPaaS training facility: Tools for building training, testing and evaluating Machine Learning, Artificial Intelligence and Deep Learning models over distributed e-Infrastructures leveraging GPU resources. Models can be built from scratch or form existing and pre-trained models (transfer learning or model reuse).
- Application composition tool: Easy and user focused way of building complex application topologies based on the TOSCA open standard, that can be deployed on any e-Infrastructure using the orchestration services.
- Infrastructure Manager: Open-source service that deploys complex and customised virtual infrastructures on multiple back-ends.
- PaaS Orchestrator: Service allowing to coordinate the provisioning of virtualized compute and storage resources on distributed cloud infrastructures and the deployment of dockerized services and jobs on Mesos clusters.
Collaboration with Industry
The EOSC Digital Innovation Hub (DIH) is in charge of establishing collaborations between private companies and the public sector to access technological services, research data and human capital. The DEEP project and DIH have established a collaboration where DEEP provides services and DIH seeks for SMEs to conduct application pilots. The services included in this agreement are:
- ML application porting to EOSC technological infrastructure
- ML implementation best practices
- AI-enabled services prototyping in EOSC landscape
Get in touch
If you want to get more information about the scientific applications adopting the DEEP-Hybrid-DataCloud solutions, please contact us!