We have won the demo contest at the virtual EOSCHub-week with a video demo showing how to easily deploy, train and share your deep learning model both in CLOUD and HPC systems!
Some slides about the demo can be found here. The video demo can be watched here!
Abstract: In this paper we propose a distributed architecture to provide machine learning practitioners with a set of tools and cloud services that cover the whole machine learning development cycle: ranging from the models creation, training, validation and testing to the models serving as a service, sharing and publication. In such respect, the DEEP-Hybrid-DataCloud framework allows transparent access to existing e-Infrastructures, effectively exploiting distributed resources for the most compute-intensive tasks coming from the machine learning development cycle. Moreover, it provides scientists with a set of Cloud-oriented services to make their models publicly available, by adopting a serverless architecture and a DevOps approach, allowing an easy share, publish and deploy of the developed models.
The last years, artificial intelligence, and more concretely, deep learning, has proved to be a very useful tool for biomedical research, medical related problems and clinical assistance. In the current situation of health emergency a massive amount of data is being produced and need to be understood using the most powerful tools available. The DEEP project is contributing to fight the COVID-19 emergency on different fronts thanks to its capacity to process huge amounts of data, to develop and share deep learning applications in a quick and easy way, and to the resources available at the project testbed. Currently, we are involved in the following initiatives:
Genetic studies
DEEP has been requested to join a project coordinated by the Institut d’Investigacions Biomèdiques de Barcelona that aims at discovering any genetic traits explaining why some people without previous pathologies get severe forms of covid-19 leading them to the ICU or even to death. The study will take genetic material (together with populational and clinical information) of 200 patients who are under 60 years old and who do not have any previous or serious chronic diseases. We want to study the difference between those patients who evolve well and those who get worse and end up in the ICU by discovering whether, at the genetic level, these latter patients have a special susceptibility. In that case this will give us an indicator of which cases are the most vulnerable and should be protected. If this indicator is found, the patients without such genetic condition could get discharged earlier and we could protect those who, besides the elderly, are likely to have serious symptoms of the disease. DEEP will provide extensive data analysis, including the development of a deep learning model that will then be published and available at our Open Catalog, and dedicated testbed resources.
X-ray images classification
Building on our image clasification module, DEEP is collaborating with the University Hospital Marqués de Valdecilla in order to develop and share a new module trained to classify chest x-ray images that will act as an assistant for the physician and will help with the patients triage. In the current state of health alarm, huge amounts of simple chest x-rays are being produced daily. Due to the saturation of the medical systems, professionals with no x-ray experience are being forced to interpret the chest images, and must systematically resort to the advice of a radiologist who is overwhelmed with consequent delay in diagnosis. Under these circumstances, a reliable automatic triage system to assist diagnosis using simple chest x-rays would greatly expedite patient management. Although this project focuses on patients with COVID-19, the developed tools will be equally applicable to other diseases with pneumonia and will be made available at the Open Catalog.
Data science to understand confinement effectiveness
European countries have adopted strict confinement measures to fight the COVID-19 spread. The Spanish National Research Council, in cooperation with the Spanish National Microbiology Center from the Health Institute Carlos III, is using data science and computing techniques in order to understand the effectiveness of these measures in Spain. The project is following a multidisciplinary approach involving computing, demography, physics and migration experts; studying high-resolution massive data to gain insights in how mobility and social contacts have changed since the measures were enforced and how these changes are influencing the COVID-19 incidence. These data are then leveraged by computational models (based both on artificial intelligence and mechanistic models), allowing to study different scenarios towards the end of the confinement measures. In this regard, the DEEP-Hybrid-DataCloud stack is being used to develop the AI models, that will be published in the Open Catalog and served through the DEEP as a Service component.
Abstract: Internet of Things (IoT) has enabled physical devices and virtual objects to be connected to share data, coordinate, and automatically make smart decisions to server people. Recently, many IoT resource slicing studies that allow managing devices, IoT platforms, network functions, and clouds under a single unified programming interface have been proposed. Although they helped IoT developers to create IoT services more easily, the efforts still have not dealt with the monitoring problem for the slice components. This could cause an issue: thing states could not be tracked continuously, and hence the effectiveness of controlling the IoT components would be decreased significantly because of updated information lack. In this paper, we introduce an information-centric approach for multiple sources monitoring issue in IoT. The proposed model thus is designed to provide generic and extensible data format for diverse IoT objects. Through this model, IoT developers can build smart services smoothly without worrying about the diversity as well as heterogeneity of collected data. We also propose an overall monitoring architecture for the information-centric model to deploy in IoT environment and its monitoring API prototype. This document also presents our experiments and evaluations to prove feasibility of the proposals in practice.
Abstract: Today, almost all clouds only offer auto-scaling functions using resource usage thresholds, which are defined by users. Meanwhile, applying prediction-based auto-scaling functions to clouds still faces a problem of inaccurate forecast during operation in practice even though the functions only deal with univariate monitoring data. Up until now, there are still very few efforts to simultaneously process multiple metrics to predict resource utilization. The motivation for this multivariate processing is that there could be some correlations among metrics and they have to be examined in order to increase the model applicability in fact. In this paper, we built a novel forecast model for cloud proactive auto-scaling systems with combining several mechanisms. For preprocessing data phase, to reduce the fluctuation of monitoring data, we exploit fuzzification technique. We evaluate the correlations between different metrics to select suitable data types as inputs for the prediction model. In addition, long-short term memory (LSTM) neural network is employed to predict the resource consumption with multivariate time series data at the same time. Our model thus is called multivariate fuzzy LSTM (MF-LSTM). The proposed system is tested with Google trace data to prove its efficiency and feasibility when applying to clouds.
Accelerated computing systems play important roles for delivering energy efficient and powerful computing capabilities for computational-intensive applications. However, the support for accelerated computing in cloud is not straightforward. Unlike common computing resources (CPU, RAM), accelerators need special treatment and support at every software layer. The maturity of the support strongly depends on specific hardware/software combinations. A mismatch at any software layer will make the accelerators unavailable for end-users.
The DEEP-Hybrid-DataCloud project aims at developing a distributed architecture to leverage intensive computing techniques for deep learning. One of the objectives of the project is to develop innovative services to support intensive computing techniques that require specialized HPC hardware, such as GPUs or low-latency interconnects, to explore very large datasets. In the project, the support for accelerators are carefully treated at all software layers:
Support for accelerators at hypervisor/container level: During the project, GPU support in udocker, the portable tool to execute simple Docker containers in user space, has been significantly improved. Current version of udocker can automatically detect GPU drivers on host machines and mount it to containers. The improvement allows udocker to execute standard containers with GPU support from DockerHub like tensorflow:latest-gpu without modification. The support for GPU in other container and hypervisor drivers is also analyzed, tested and deployed on the project testbed in combination with higher cloud middleware framework whenever possible.
Support for accelerators at cloud middleware framework level: The project testbed consists of sites with different cloud middleware frameworks including Openstack, Apache Mesos, Kubernetes and also HPC clusters. All these cloud middleware platforms are deployed with GPU supports. As GPU virtualization is supported only on newer GPU cards, Openstack sites mostly provide support for GPU via PCI passthrough approach in KVM hypervisor. Kubernetes sites have GPU support via NVIDIA device plugin and Mesos provide access to GPU via its own executor which mimics the nvidia-docker approach. Finally, the GPU support on HPC sites is provided by the portable, user-space execution tool udocker mentioned above.
Support for accelerators at PaaS orchestrator level: In the project,the information system (Cloud Info Provider + CMDB) has been extended in order to collect information about the availability of GPUs at the sites. The GPUs can be made available through different services at the IaaS level, e.g. they can be provided through native Cloud Management Framework interfaces (e.g. Openstack or Amazon specific flavors) or through Container Orchestration Platforms, like Mesos. The TOSCA model for compute and container nodes has been extended in order to include requirements of specialized devices like GPUs, specified by users. The Orchestrator bases its scheduling mechanism on the provided information to select the best site where the resources will be allocated.
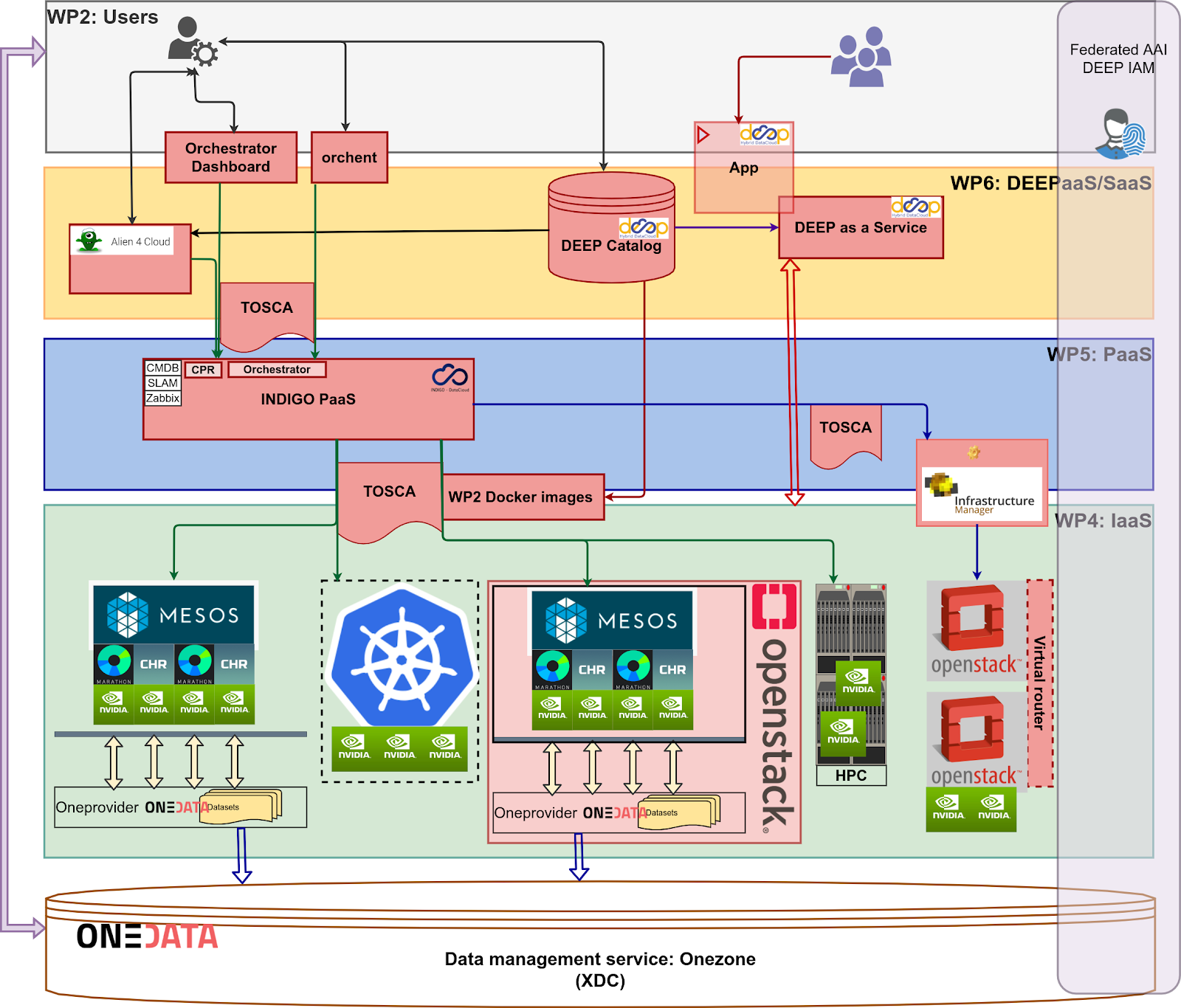
Although called a testbed, in reality it is a small scale production infrastructure, all software components and services are running the versions released in the DEEP-2 – coded named Rosetta – and are operated and managed as any other production service or platform. A diagram of the Pilot Preview is shown in the figure below.
Resources made available by project partners are nonetheless significant, one can exploit about 30 high end NVIDIA GPUs distributed across 3 cloud e-infrastructures and a data/storage management system that is federated between 3 providers with about 80TB of total storage. One of the main features is the data locality to the computing resources, allowing a more efficient computation.
Other features worthy to mention are: the cloud resource providers are part of the production EGI Fedcloud infrastructure, the data/storage management system is a “result” of a tight collaboration between DEEP-HybridDataCloud and eXtreme DataCloud – XDC projects, where storage resources from both projects are federated through the Onedata service (bottom of the diagram); users are authenticated and authorized through the Federated AAI service called DEEP-IAM (right side of the diagram).
Finally, and the most important highlight, the users can execute ML/AI applications in a production mode with long training of the models and using large datasets (some cases of the order of TBs).
Typically the HPC environments are characterized by software and hardware stacks optimized for maximum performance at the cost of flexibility in terms of OS, system software and hardware configuration. This close-to-metal approach creates a steep learning curve for new users and makes external services, especially cloud-oriented, hard to cooperate with. In exchange for the flexibility one gets access to tens of thousands of CPUs and a high performance network and storage but with little isolation between the jobs and little or no possibility for the applications to interact with services outside a particular cluster.
The DEEP-Hybrid-DataCloud project aims at developing a distributed architecture to leverage intensive computing techniques for deep learning. One of the objectives of the project is to promote the integration of existing HPC resources under a Hybrid Cloud approach, so it can be used on-demand by researchers of different communities.
The abstraction offered by our solution simplifies the interaction for end users thanks to the following key features:
Promoting container technologies for application development, delivery and execution: This approach enables easier application development, integration and delivery with CI/CD practices. It also makes applications portable and can be deployed/executed on any platform, independently from OS/libraries/software installed on host. Such containerized applications can be used in both Cloud or HPC platforms without modifications.
Using portable container execution tool in use space on HPC platforms: udocker is a basic user tool to execute simple Docker containers in user space without requiring root privileges. It enables download and execution of Docker containers by non-privileged users in Linux systems where Docker is not available. It can be used to pull and execute Docker containers in Linux batch systems and interactive clusters that are managed by other entities such as grid infrastructures or externally managed batch or interactive systems.
Standard interfaces are used to manage different workloads and environments, both cloud and HPC-based: the TOSCA language is used to model the jobs and the PaaS Orchestrator creates a single point of access for the submission of the processing requests. The DEEP PaaS layer features advanced federation and scheduling capabilities ensuring the transparent access to different IaaS back-ends including OpenStack, OpenNebula, Amazon Web Services, Microsoft Azure, Apache Mesos, Kubernetes and finally HPC environments. The user request is expressed in the TOSCA templating language and submitted to the PaaS Orchestrator. Depending on the type of request, the specific plugin will be activated in order to dispatch the task to the best compute service.
Adopting unified AAI throughout the whole stack, from the PaaS to the data and compute layer: it is implemented by the INDIGO IAM service that provides federated authentication based on OpenID Connect/OAuth20 mechanisms. A SSH PAM module has been developed in order to allow users to login via ssh using their IAM access token instead of password. The users are automatically provisioned on the HPC cluster starting from the list of users registered in IAM and belonging to a specific group. Each IAM user is mapped onto a local account.
A REST API gateway for submitting and monitoring the jobs from outside the HPC site. QCG-Computing is an open architecture implementation of SOAP Web service for multi-user access and policy-based job control routines by various queuing and batch systems managing local computational resources. This key service in QCG is using Distributed Resource Management Application API (DRMAA) to communicate with the underlying queuing systems. QCG-Computing has been designed to support a variety of plugins and modules for external communication as well as to handle a large number of concurrent requests from external clients and services.
We are pleasured to announce that DEEP-Hybrid-DataCloud consortium has signed a collaboration agreement with EOSC-DIH, aiming at boosting the dissemination of DEEP offering and fostering the adoption of project solutions by SMEs. This collaboration will allow to perform industrial pilots, which will increase the acceptance in the market of DEEP solutions.
The EOSC DIH is a mechanism for private companies to collaborate with public sector institutions to access technical services, research data, and human capital.
The goal of the collaboration agreement is twofold, the promotion of the collaboration among DEEP-Hybrid-DataCloud and SMEs, and the dissemination of DEEP results through the EOSC-hub channels. The activities envisioned are:
Inclusion of the DEEP-Hybrid-DataCloud services in the EOSC DIH offering
ML implementation best practices and ML application porting to EOSC technological infrastructures
AI-enabled services prototyping in EOSC landscape
Identify SMEs interested in DEEP results, providing the resources to set up a business pilot, and facilitating the adoption of DEEP offering by SMEs
Disseminate DEEP offering through the EOSCH DIH channels to promote the interaction among providers, SMEs and DEEP consortium
The DEEP Open Catalog provides ready to use modules for Artificial Intelligence, Machine Learning and Deep Learning models that can be executed in a wide variety of computing platforms. These include local laptops, production servers, supercomputers and e-infrastructures supporting the DEEP Hybrid-DataCloud software stack.
The versatility of the DEEPaaS component, which provides a REST API to serve machine learning and deep learning models, has allowed to introduce additional functionality required to perform the prediction phase from the command line interface. This is required to perform batch execution of prediction jobs to be run, for example, on Local Resource Management Systems (LRMS) such as SLURM, within a cluster of PCs. This allows, for example, to classify thousands of audio files using an Audio Classifier module in the DEEP Open Catalog in an unattended manner.
We wanted to determine how easy it was to run these modules on a public Cloud provider such as Amazon Web Services. Indeed, existing services such as AWS Batch provide the ability to deploy virtual elastic clusters, even with GPU support, that execute Docker-based jobs and can auto-scale to zero in order to support a pay-per-usage approach.
To this aim, we used the open-source SCAR tool, which allows to create highly-parallel event-driven file-processing serverless applications that execute on both customised runtime environments on AWS Lambda and in AWS Batch compute environments. As it can be seen in the newly added deep-audio use case for SCAR, this tool uses a YAML file to describe the job to be executed (in this case based on the deephdc/deep-oc-audio-classification-tf Docker image in Docker Hub).
The following figure shows the dashboard of the developed service. It consists of a web-based application that provides seamless access to the service to the DEEP’s user community. The service provides the ability to select a model from the DEEP Open Catalog (from those integrated so far) so that, whenever a new file is upload, this triggers the execution of prediction phase of the model, using this file as input. This is executed on a dynamically provisioned cluster of machines than can leverage both CPUs and GPUs (if the models supports this feature). Additional computing nodes are added if many files are pending to be processed. Also, the virtual clusters auto-scales to zero whenever all the files have been processed, thus providing seamless event-driven prediction for DEEP models.
The following figure summarises the architecture of the service. The web service has been integrated with the DEEP IAM through the help of Amazon Cognito’s Federated Identities in order to provide easy access for existing DEEP users. Uploading a file to the Amazon S3 bucket triggers the execution of an AWS Lambda function (created through SCAR) that automatically converts the request to a Batch job submitted to a specific compute environment, what triggers the deployment of additional virtual machines to perform the processing (prediction) of the files.
As a summary, the flexibility of DEEPaaS and the availability of pre-trained modules in the DEEP Open Catalog has facilitated the highly scalable execution of these models on a public Cloud provider such as Amazon Web Services. SCAR is able to provide serverless computing for scientific applications to be run directly on AWS Lambda. However, the large size of the Docker images in the DEEP Open Catalog required to support the event-driven execution of more resource-intensive computing services as is the case of AWS Batch.