First part: Running a module locally for prediction
Deep Learning is nowadays at the forefront of Artificial Intelligence, shaping tools that are being used to achieve very high levels of accuracy in many different research fields. Training a Deep Learning model is a very complex and computationally intensive task requiring the user to have a full setup involving a certain hardware, the adequate drivers, dedicated software and enough memory and storage resources. Very often the Deep Learning practitioner is not a computing expert, and want all of this technology as accessible and transparent as possible to be able to just focus on creating a new model or applying a prebuild one to some data.
With the DEEP-HybridDataCloud solutions you will be able to start working from the very first moment!
The DEEP-HybridDataCloud project offers a framework for all users, and not just for a few experts, enabling the transparent training, sharing and serving of Deep Learning models both locally or on hybrid cloud system.
The DEEP Open Catalog (https://marketplace.deep-hybrid-datacloud.eu/, also known as “marketplace”) provides the universal point of entry to all services offered by DEEP. Its offers several options for users of all levels to get acquainted with DEEP:
- Basic Users can browse the DEEP Open Catalog, download a certain model and apply it to some local or remote data for inference/prediction.
- Intermediate Users can also browse the DEEP Open Catalog, download a model and do some training using their own data easily changing with the parameters of the training.
- Advanced Users can do all of the above. In addition, they will work on more complex tasks, that include larger amounts of data.
The DEEP-HybridDataCloud solution is based on Docker containers packaging already all the tools needed to deploy and run the Deep Learning models in the most transparent way. No need to worry about compatibility problems, everything has already been tested and encapsulated so that the user has a fully working model in just a few minutes.
To make things even easier, we have developed an API allowing the user to interact with the model directly from the web browser. It is possible to perform inference, train or check the model metadata just with a simple click!
Let’s see how all this work!
In this post we will show how to download and use one of the available models from the DEEP Open Catalog in our local machine. These instructions will assume the user is running on linux but the docker containers can run on any platform.
First we browse the catalog and click on the model we are interested in among the many that are already in place. Once we click on the model of our choice we will see something similar to this:
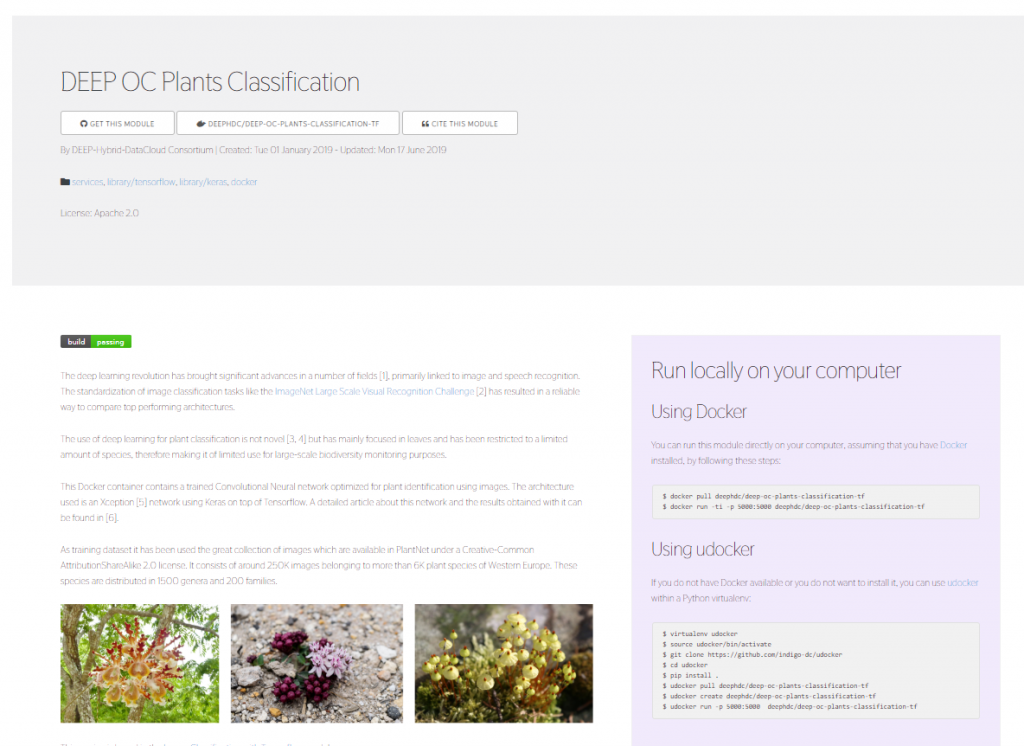
In this case we have selected a module classifying plant images according to their species using a convolutional neural network architecture developed in Tensorflow. Under the name of each of the modules in the DEEP Open Catalog we find some useful links:
- Link to the GitHub repository including the model source code
- Link to the Docker Hub repository of the docker containing all the needed software configured and ready to use
- In case this is a pretrained model, a link to the original dataset used for the training.
Before starting we need to have either docker or udocker installed in our computer. We will be using udocker since it allows to run docker container without requiring root privileges. To install udocker you can just follow this very simple instructions:
virtualenv udocker
source udocker/bin/activate
git clone https://github.com/indigo-dc/udocker
cd udocker
pip install .
We can now just follow the instructions on the right part of the module page and type the following commands:
udocker pull deephdc/deep-oc-plants-classification-tf
udocker run -p 5000:5000 deephdc/deep-oc-plants-classification-tf
This will download (pull) the docker container from Docker Hub and run it on our local machine. The run methods includes the option -p 5000:5000 which maps the port 5000 from our local server into the port 5000 in the container.
We have now the DEEP API running on our localhost!
You can go to your preferred web browser and enter localhost:5000 in the address bar. This will open the DEEP as a Service API endpoint. It looks like this:

As you can see in the image different methods can be chosen. You can either return the list of loaded models (in this case we are just running the plant classification example) or the metadata of your models. You can also do some prediction on some plant image of your interest or even train the classification neural network on a completely new dataset. All this directly from your web browser.
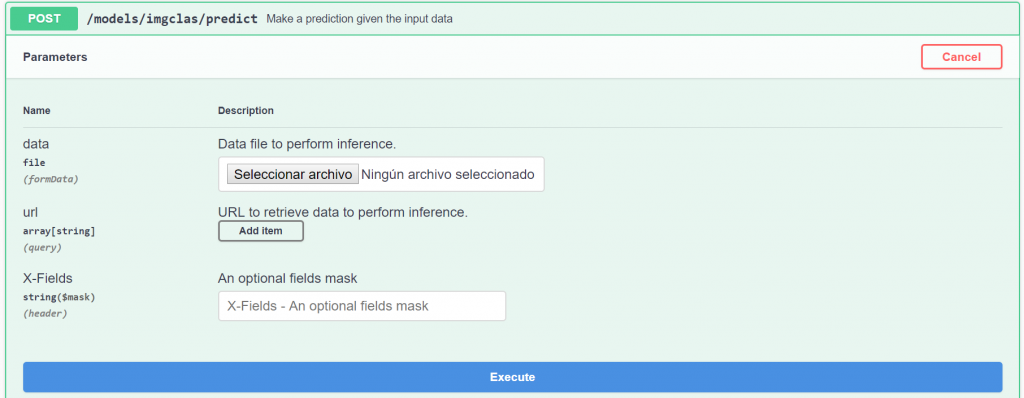
Let’s now try out the prediction method. We can either use a local file or the URL to some online plant image to perform the classification. For this example we will use a locally stored image.
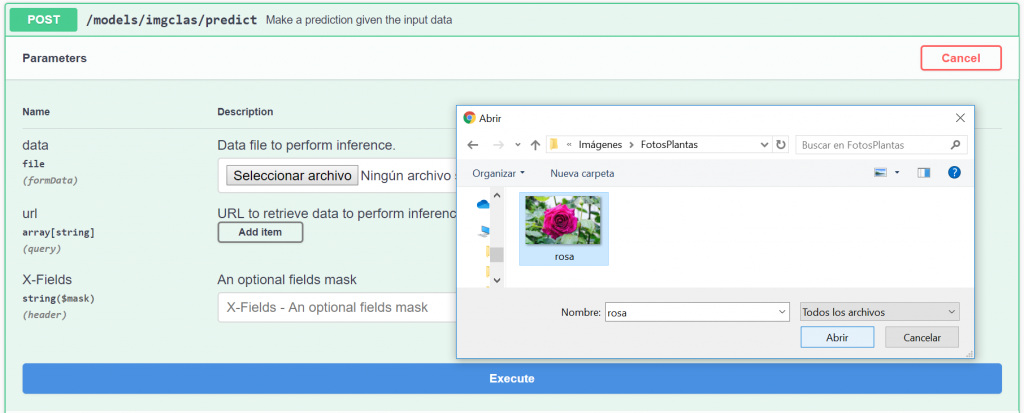
We click on Select File and browse our file system for the image we are interested in. In this case we will use the image of a rose. If you want to reproduce this example you can find the image here.
Now that we have selected the image we can click on Execute. The first time we perform a prediction with a given model the process takes a little while since the Tensorflow environment must be initialized. Afterwards, the prediction will be extremely quick (less than one second in many cases).
The prediction for our roses gives us the following output:
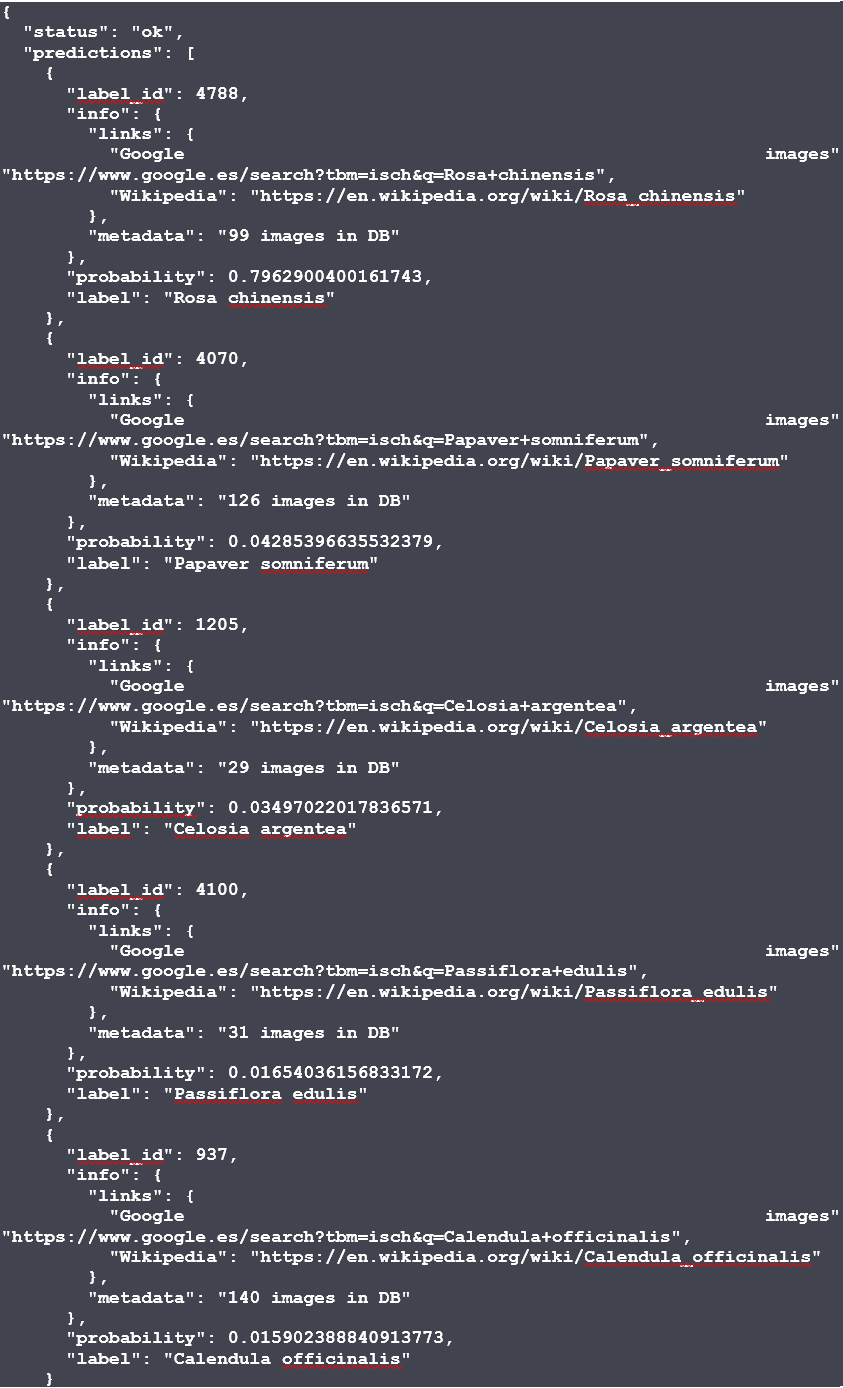
The result shows us the 5 most probable species. The most probable one is the Rosa Chinensis with a probability of 80%. Our module has predicted correctly! Together with the prediction we can find a link pointing to Wikipedia to check the species.
The output is given in JSON format that can be very easily integrated with any other application needing to access the results.
In this example we have seen how to use one of the DEEP-HybridDatacloud modules running a Deep Learning model in just a few simple steps on our local machine.
If you want more detail, you can find the full documentation here.
In next posts we will see how to train a model using the DEEP API and how to run on a cloud system. Stay tunned!


{kind=link}